In this series of 4 blogs, I will discuss our journey towards building an enterprise Data Processing Platform (DPP). We use DPP as a central platform to
- Collect high velocity, volume, and variety data from multiple sources – namely, all of the ingredients our very diverse business needs to produce information and percolate insights in a multitude of locations, business lines, and operating environments.
- Process (this usually means transform), consolidate and maintain hundreds of Tera Bytes of data being generated across our organization so that it is available to support administrative, operational, and compliance needs.
- Enable an enterprise-wide, single source of truth that not only makes it easier to find and use data for operational analytics, but also generates new insights from less “Business-Intelligence-friendly” data to drive business decisions.
Figure-1 : Data Processing Platform Eco-system
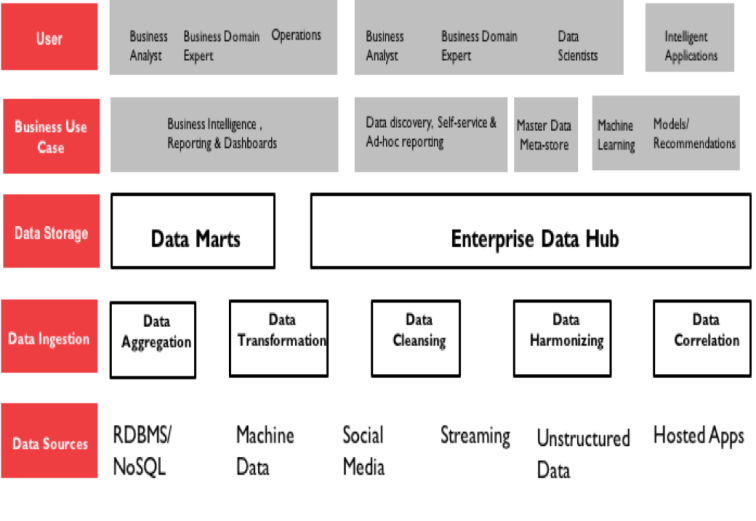
Why is there a need to build a unified data processing platform? Working alongside multiple clients while prosecuting business , we have observed that patterns in data engineering and data storage are fairly common regardless of the line of business. Our job is to master and optimize those patterns regardless of business domain or systems that produce data, delivering services like descriptive analytics (reports), self-service and data discovery, insights or highly evolved outcomes through the most advanced analytical methods conceivable. Our starting point is this data processing platform. Whatever we deliver downstream, we support it through DPP.
Before constructing the basic model for unified data processing platform, we first identified key factors that would influence the general (holistic) architecture as well as a range of subcomponents for our DPP ecosystem. Most important design considerations for us are described below:
- An open (i.e. vendor neutral, and open source where possible), extensible (i.e. we can add new modules to perform new functions) design that enables low-overhead integration with our existing corporate infrastructure and business applications.
- A horizontally scalable architecture, with module and platform-level facilities to scale up or scale down. We knew we needed to start small with computing resource for our initial modules and use cases, with just the right amount of computing resource to support our design for foundational software modules with little upfront cost so that we could justify ROI before scaling up.
- Connectivity and storage sufficient to ingest and retain high velocity, high volume, and high variety data coming from disparate sources including but not limited to discrete event data (single records), log data (partially structured), machine generated data (high entropy), social media, RDBMS, NoSQL, text/narrative data, audio call recordings (binary, often uncompressed), telephony data, video data (binary, encapsulated/encoded), emails, web clickstreams, web/SMS chat data etc.
- Multiple programmatic (ideally configurable, without coding) modalities for accepting data inputs – push and pull, scheduled and on demand, streaming and batch.
- A “schema on read” approach to capture and retain data in raw format, as well as a processing flow to transform the raw data for usability
- Ample on-premise (vs cloud) computing resource, taking into consideration that most of the data we need to address resides on premise and the ingress and egress costs would turn otherwise cost-effective cloud infrastructure into a high-latency, high-cost computing environment.
- Data quality assurance, achieved through sanitization and harmonization of disparate sources sufficient to handle inconsistencies across those sources using a rules-driven approach.
- Support for Massively Parallel Processing (MPP) systems to clean, aggregate and conform data to a standard format.
- Data service layers that provide the right interfaces for different stakeholders (business analysts, reporting groups, data scientists) to consume data, even if that means repackaging the same essential data in multiple formats or at different frequencies/levels of aggregation.
- Platform support for self-service data discovery, such that business users can find and collect data that they seek without direct IT involvement.
- Enterprise-grade features to enable service for a large such as high availability, disaster recovery, and multi-tenancy so that distinct data sets, applications,and procedures for multiple clients co-exist in a common cost and compute oriented infrastructure while remaining physically isolated from each other for regulatory or compliance matters.
- Security at rest and in motions, along with trace-able access control.
- Platform infrastructure management that ensures the availability of tools to manage problems like node failures, bad hard drives, stopped services, tool versions compatibility, and software upgrades.
- Automated purge or relocation of data to more cost-effective persistence models, since most operational data loses its relevance with time and creates a savings opportunity via less-expensive storage.
In Part 2 of this blog series, I will dig into some of the specifics around tools and frameworks we used to DPP.

One thought on “Building a Scalable Data Processing Platform for Analytics – Part 1”