While building a predictive model using logistical regression (to predict customer churn), we used data points from multiple systems/sources including customer details, demographic data, customer billing and payment history, customer usage history, current plan and contract details, interactions with customer support etc. One of the challenges was how to utilize rich contextual information captured during end user interactions with customer service/support (in the form of text messages, chats, email messages, voice data transcriptions) for training our classification model.
In this blog, I will primarily talk about how we converted very high-dimensional text data into numerical input features for our classification model. In a subsequent blog, I will provide details about model selection (for predicting customer churn) along with mechanism we used to measure prediction accuracy.
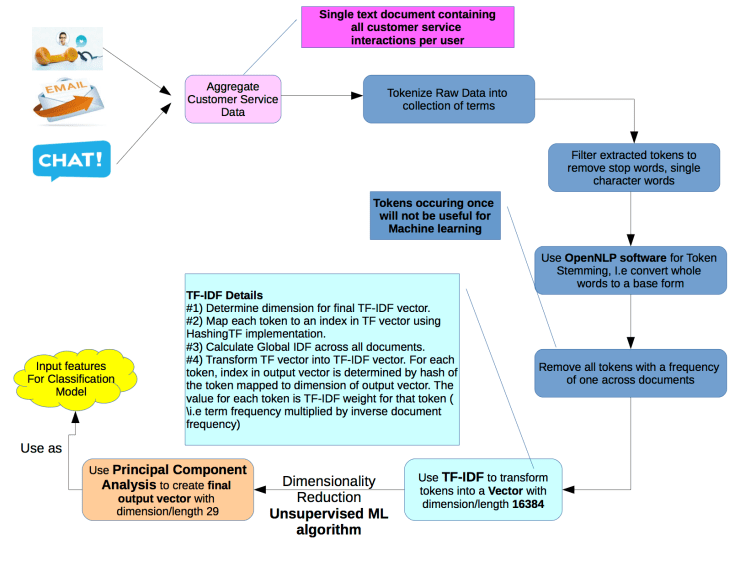
First step in this process was to create a text document representing a given end user’s interaction with customer service over time. For example, if an end user interacted with customer service twice via email channel and once via phone channel, we would combine contents of all emails and response from customer service as well as transcription of audio call recording into a text document.
Second step (once we had aggregated data as described in Step 1) involved using a technique called Term Frequency Inverse Document Frequency (TF-IDF) and Feature Hashing to extract structured features from text data with. This technique weights each term in a piece of text (called a Document) based on its frequency in the document (Term Frequency). Terms occurring many times in a document receive a higher weight in the vector representation relative to those that occur few times in the document. A global normalization, called Inverse Document Frequency, is determined based on the frequency of a given term in all documents, which reduces weight of terms that are common across all documents. Output of this step was a dimensional vector with a dimension/length of 16384 containing numerical features created from contents of the document.
In Third step, we used Dimensionality Reduction, a form of Unsupervised Machine Learning to take output data (generated in Step 2) with dimension D and extract a representation of data with K dimensions, where K was much smaller than D. Dimensionality reduction was implemented using Principal Component Analysis (PCA) algorithm available in Apache Spark MLLib. In our case, we were able to take a vector with dimension/length of 16384 and extract an equivalent output vector representation with dimension of 29. When applying PCA on TF-IDF datasets (generated in Step 2), we choose a value of 29 for output dimensions as it ensured that we were capturing at-least 99% variability of the original data. Output of this step was then used as input features for our supervised learning algorithm, which bound memory usage of our model, both in training and production.