Many traditional applications fail to handle exponential increase in volume and velocity of business data being generated in today’s day and age. In this post, I want to share my experiences during our journey to move our commercial offering from a traditional java RDBMS architecture to move core processing logic to MapReduce Programming model (on Hadoop) and eventually to Apache Spark.
The figure below shows our traditional aproach to aggregate data:
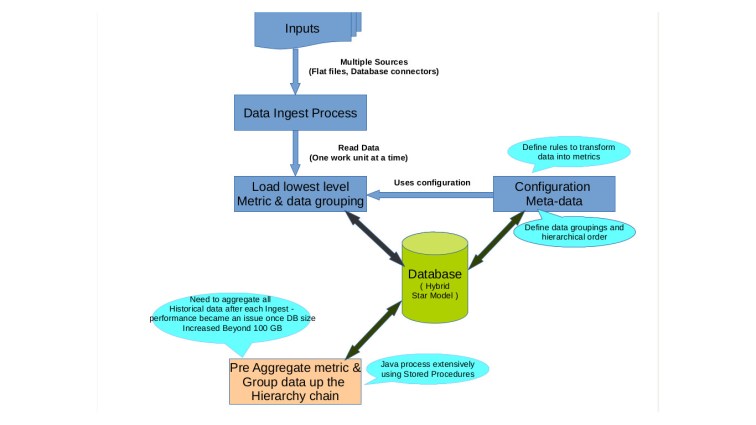
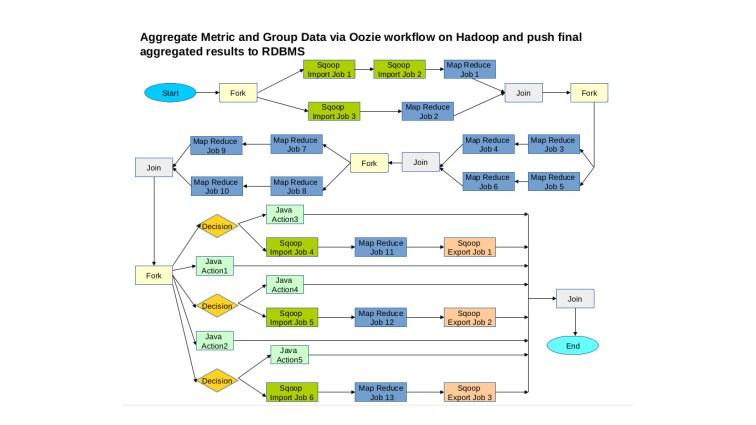
As the amount of data we aggregate increased from a few hundred Giga Bytes to a couple of Tera Bytes, we started having performance/scale issues with our traditional java RDBMS approach. We moved our core aggregation logic to Hadoop (orchestrated via Oozie Workflow) as show in figure below :
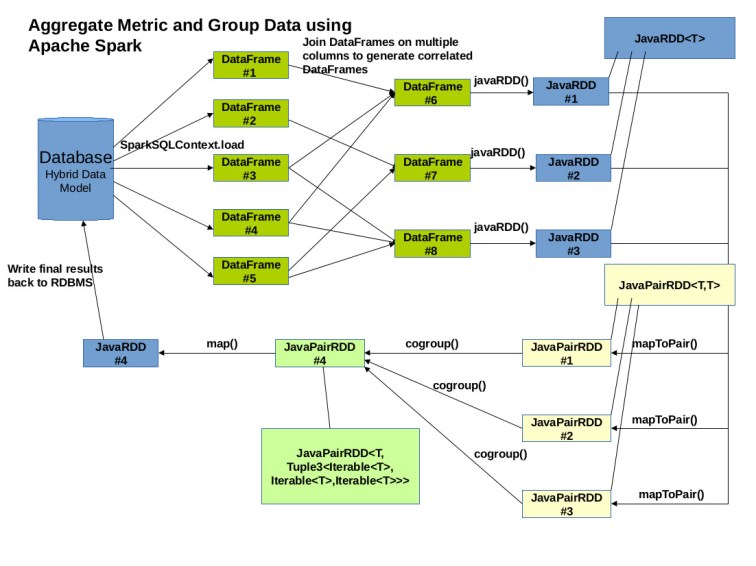
With Hadoop, although we had significant performance improvement over traditional approach, the processing still took quite some time because of heavy I/O, generation of intermediate files during each step of Oozie workflow. To run our aggregation logic in real time, we eventually moved it to Apache Spark as described below :